Chrony Rate Fluctuations
The following graphs show the fluctuations in the rates of the system
clock and of the real time clocks on a variety of computers on the theory
network. Until June all were synchronize against the same system, ntp.ubc.ca, a stratum 2 ntp server on campus ( the time delay is on the order of 100s of microseconds to that machine from any of these computers). as the top graph shows that server had a 3-4 msec sawtooth drift against GPS time. Thereafter, string was synchronized against tick.usask.ca, a stratum 1 server synchronized against GPS. In Sept, 2007, string was put onto ntp and sychronized against a stratum 0 GPS clock ( A Garmin 18LV GPS receiver with a PPS output) against which it maintains a roughly 2-3 microsecond offset. All of the other clocks are chrony synchronized against it. It is less a msec via switches away from all of the other clocks.
Graphs from previous weeks.
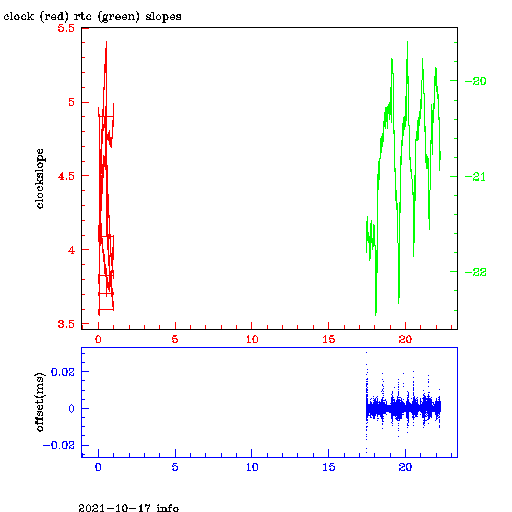
The following graphs plot the rate of the system clock vs the ntp server
(red line and left hand scale) and the rate of the RTC vs the system
clock(real time clock-- the CMOS clock)( dotted lines and right hand scale)
against the time in days after 00:00 on the date shown. The rates are in
units of microseconds per second. These rates are determined by comparing
the reading on the system clock with the ntp determined times on the NTP
server to adjust the rate of the system clock, and the rate of the RTC vs
the system clock.
Note that the strong correlation between the rate fluctuations suggests
that the system clock is the primary source of noise, and that in general
the RTC has better stability than does the system clock.
In the graphs for the week ending Feb 11, the huge instability in the case of one of the machines, info,i and of the other machines after they were restarted on Feb 9, is
unexplained. There seems to be an instability in the operation of chrony.
The restoration of a semblance of order after the 10th was done by
decreasing the maxupdateskew to 1/5 (from unlimited).
Dilaton was the most accurate clock in its rate fluctuations before that
restarting, but not afterwards.
Well, I have finally tracked down the problem. That stratum 2 server
ntp.ubc.ca stinks. I got a gps device with a PPS output, which I hooked up
to a couple of the machines. The most interesting is string, which had some
of the most unstable behaviour with chrony and ntp.ubc.ca. in the following
graph, I have plotted the response of string to the gps clock ( with chriny
switched off) to ntp.ubc.ca and to tick.usask.edu, a stratum 1 server.
The huge regular sawtooth waves come from ntp.ubc.ca. Not only is the
system on average about 3ms fast, its offset varies regularly.
tick.usask.edu is very much better behaved-- considering that it is almost
10 msec away ( peer delay), its accuracy differs from the gps time by only
about a few tens of a microsecond. (The "line" across the top is the gps
time, with a width, a jtter of about 3 microseconds. The jagged line
starting at 24 hr is tick.usask.ca, while the huge oscillation is
ntp.ubc.ca, a supposed stratum 2 source. It may be that because it is
running SunOS, the kernel cannot regulate the system clock properly leading
to this behaviour.
(Note that in each case exactly the same overall drift has been removed
from the data-- ie the drift was determined from teh GPS clock and then the
same drift was removed from each of the other graphs.)
What is interesting is that while the gps spikes are all late ( by a few
microseconds) both the ntp sources are early. This seems to imply that the
outbound ntp packets take slightly longer than the inbound packets.
On Apr 14 all of the machines except dilaton and string were changed to get
their primary time from string, which gets its time from tick.usask.edu.
Dilaton got its time from time-nw.nist.gov, a time server located at
Microsoft but was switched to string on Apr 15.
In August, String was switched to running ntp with a Garmin 18LVC gps
receiver delivering PPS signals to ntp. The accuracy of string then became
of the order of a microsecond.
In Nov 07, the bottom graphs were added. These give the measured offsets and
round trip delay times for string as the stratum 0 source from each of the machines. The large ( up
to 1 sec) round trip times seem to be due to problems with the switches
installed in Physics (Cisco Gigabit switches) which seem to insert
latencies of up to 2 seconds in routing the ntp packets between the various
machines and string. monopole, charge, gauge, boson, dilaton, flory, info,
fluxon are all on the same set of switches, so the delays come from single
switches.


This is especially obvious in the week ending Feb 18 Some of the machines
have huge (10ppm) fluctuations in the rate, and at exactly the same time,
others (eg charge) are running in the .2 ppm range of fluctuations.
Ie, these fluctutions are not coming from the source ntp.ubc.ca. They seem
to be inherent in the way chrony is setting the rates.
Since the time between comparison of the system clock vs the NTP server is of
the order of 100-1000 sec (peer delay is .6ms typically) , the noise rate in
the case of the best system would correspond to less than a millisecond drift
Notes:
- Dec 30/07-- The glitch in the timing (see orbit) at 30.65 was because
string lost contact with the GPS unit for half an hour, and the backup
units (ntppool) were out by 480 msec.
- Jan 8/08-- dates on "string" graph changed from localtime to utc to agree
with other graphs.(8.8-9.1)
- Jan 9/08-- Testing of ntp made string .15 msec out of sync. Thus the
glitches in the chrony plots on Jan 9.1
- Jan 18/08-- System crash at about Jan 18.0
- Jan 19/08-- flory switched to ntp at 19.1 ntp allowed the clock to go
mad for the first while reachind a 60ms offset, and slowly over the next
day dropped to a 2-4ms offset (a factor of 100 off the approx 10-20usec
offset with chrony). At 19.815 ntp restarted with a maxpoll of 7, rather than
10 to make it equivalent to the old run of chrony.
- Jan 22/08-- all running chrony are reniced to -12 (which is the nice
value that ntp runs under.)
- Jan23/08-- chronyd changed to 1.23pre1 with priority change on info-- set to run at max priority at 23.78
- Feb 19/08 15:25PST (23:25UTC)-- chronyd on gauge changed for a new version which
has reduced tendency to shorten the poll interval. (the old version tended
to go for shorter poll intervals)
- Apr 2(Mar 33)/08 -- String crashed for about 8 hours-- it is the
time server.
dilaton
Core 2 Duo 2.8 GHz Intel , 3GB ram,Gb ethernet
gauge
One 750MHz Intel Pentium III Processor, 256M RAM, 100Mb
ethernet
monopole
3GHz Dual core, 4GB Ram, 1GHz ethernet
charge
Dual core 3 GHz Intel Pentium 4 Processor, 3GB RAM, 1Gb
ethernet
orbit
One 935MHz Intel Pentium III Processor, 256M RAM, 100Mb
string
One 1.6GHz Intel Pentium 4 Processor, 512M RAM, 100Mb
fluxon
One 2.67GHz Intel Pentium 4 Processor, 0.99GB RAM, Gb
ethernet
boson
Two 2.8GHz Intel Pentium 4 Processors, 0.98GB RAM, 100Mb
info
Quad 2.7GHz Intel Pentium i5 Processors, 8GB RAM, 1Gb
ethernet
flory
Two 3GHz Intel Intel(R) Pentium(R) D CPU 3.00GHz Processors,
1GB RAM, 100Mb
These rate fluctuations do not represent the actual clock accuracy,
(in general chrony keeps the clocks to within a millisecond or less) but
do represent the stability in the onboard system clock (driven from the
bus frequency) and to some extent the real time clock. As chrony works,
it measures the real time clock against the system clock, so an unstable
system clock would produce an apparently unstable real time clock. In
general the RTC seems to be more stable than is the system clock ( the
correleated fluctuations in the system and RTC would suggest that a fair
amount of the RTC instability comes from the system clock, rather than the
RTC itselfi-- although this may be belied by the fact that the rate
fluctuations for the rtc clock and the rate fluctuations for the system
clock are very different in scale. )
To investigate whether the oscillations with about a 1.5 hour period in
most of the chrony graphs are real fluctuations (eg caused by temperature
fluctuations with a 1.5 hr scale) or are produced by the clock algorithm of
chrony itself, I placed flory onto ntp as the client instead on Jan 19
2007. What is striking is how long it took the ntp client to come into
sync. In the graph below a plot of the offsets, the rate set by ntp on
startup. NOte that there was no drift file, so ntp had to figure out what
the drift rate of the clock was on its own. But the behaviour was such that
the clock, which was within less than a ms of the correct ntp time before
the change to ntp and running at the correct rate (having been set by chrony),
ntp caused the clock to rapidly go to a -20ms offset overcorrect to a 60ms
offset and then take hours to finally get the clock back to about +5ms.
Overnight, it went to a poll number of 10 (2^10 sec) and the switch between
flory and string seems to have occasionally introduced 5-10ms delays (
about 20% of the time). However, ntp over the next 8 hours never managed to
get the offset below 3-6ms. At daynumber 19.815 I restarted ntp with
maxpoll 7 ( which was the same as I had run chrony at) and the offset now
rapidly settled down to about 100usec., and began to have both positive and
negative excusions. Ie, ntp seems to have a really hard time dealing with
transient effects (like being started without a drift file).
Chrony on the other had even with a one second initial offset settles down
to a locked, minimal offset conditions in less than an hour.

Chrony vs NTP comparison in clock control
If we compare the standard deviation of the offset produced by chrony
over the week Jan 13.5-18.3 UTC with the standard deviation from ntp over
Jan 20.0-Jan 21.88, I get
- Chrony: Mean offset= -1.5usec Std Dev= 20.1usec
- NTP: Mean offset= -0.16usec Std Dev= 53.1 usec
Ie, chrony controls the clock a factor of three better than does ntp.
(Remember that this is on the same maxpoll of 7 for both)
On 21.0 the ntp version was changed from 4.2.0 to 4.2.4. After that change
the standard deviation of the offset was 37 usec. Ie, the control got
significantly better, but still almost 2 times worse than chrony.
On the other hand, the mean rate and rate fluctuations (standard deviation)
are
- Chrony: Mean= 25.26 Std Dev= .091 (PPM)
- NTP: Mean= 25.35 Std Dev= .025 (PPM)
Ie, while the rate seems to be much better controlled with ntp ( and it
is not clear how much of that rate fluctuation is real, and how much an
artifact of the algorithms) the offset is much more poorly controlled by
ntp.
The mean time between measurements is 126.5s for chrony, and is 123.9 for
NTP both at maxpoll 7 (If they really used the max accurately both would be
128 sec between ntp queries). Ie, the better offset control by chrony does
not come at the expense of more measurements by chrony.
The one place that ntp seems to do significantly better than chrony is the
round trip time. For ntp the round trip time is 159usec with a standard
deviation of 6.6usec, while for chrony the average is 178usec with a
standard deviation of 28usec. Ie the standard deviation is four times
worse.
-Jan 24-- I have discovered both that ntp does even worse than stated
in both the round trip time and in the offset variance. NTP has a clock
filter algorithm which takes the shortest roundtrip of the last eight
samples and reports that as the round trip and also uses the offset
associated with that shortest as the offset. Thus there are many
repetitions ( usually of the order of 6 in a row). chrony's measurements
wee the actual measured offsets and round trips on each of the measurement
events.
i(Jan 24/08)--The ntp algorithm only submits the measurement for use in the clock control
algoritm if the most recent measurement is also the best of the last 8.
(actually the selection criterion is slightly more complicated as the
"round trip" used in the algorithm is equal to the actual round trip plus
the event number (most recent is 0) times the freq error (15PPM) times the
time since the last sample, or the freq times the last sample.
Further investigation seems to indicate that this is primarily due to
the higher priority that ntp runs at (ntpd sets its priority to -12 while
chrony was running at the default of 0) If I eliminate all round trips with
a delay of greater than .2ms, the standard deviation for chrony drops to 7usec,
the same as ntpd. Of course getting rid of those items for the statistics
does not eliminate their effect on the offset noise and on the clock
discipline. I am now running the chrony processes with a nice value of -12.
After ntp 4.2.4 was started, the mean round trip drops to 150usec and the
standard deviation to 5usec. This makes the higher offset control by chrony even more impressive.
However the measurements for ntp were done on the weekend, while those for
chrony were done during the week. (also see above about the niceness)
Response to Transients
Comparison of Chrony and NTP discipline of a clock over ADSL link
These two graphs represent the very different response of chrony and ntp to
glitches in the drift rate of the clocks. I have no idea why the clocks
suddenly have drift rate changes, changes which seem to effect both the
system clock and the rtc but at very different magnitudes.
In the case of chrony a 2PPM change in the rate, causes a 100-200usec change
in the offset, but that disappears withing about 5 min and the clock
settles down to its new rate.
In the case of ntp, a 0.4 PPM change in the rate causes a 600usec change in
the offset, and this offset takes a about 6 hours to disappear to settle
back down to the pre glitch level. Now of course the detailed structure of
the rate change is unknown since all we have is the offset and rate as
reported by ntp.
Thus, a glitch which is 1/5 as big produces about 5 times as big a change
in the offset, and the time for this change to disappear is about 20 times
as long.
These are a day's worth of the comparison of chrony (left) and ntp(right)
comparison against a gps PPS clock. The client is a computer connected to
the server (string) via an ADSL line. We note again that chrony disciplines
the clock with a significantly smaller variance ( factor of 3) than does
ntp. The noise in this case comes primarily from the fluctutations in the
delay of the ntp packets to and from the server due to the ADSL variations.
We note that the noise is not simply random, but fluctuates during the day.
Note also that there is a 0.3 msec bias such that the compter clock is 0.3
ms slow of true gps time.
The reduced small scale noise in ntp is probably due to the fact that
ntp throws away about 7/8 of the data points in the clock filter, and the
exponential feedback form of the discipline. chrony uses all data points
which satisfy minimal conditions, and uses a fit to the last n points,
where n in this case is around 64 points. Also chrony drops its poll
interval from maxpoll more readily than does ntp, so that the average poll
time is about 70 sec for chrony and 120 for ntp, with a maxpoll time of
128s.
The response of ntp to the change in rate is slow. Linux in the more recent
kernels has had a highly inconsistant calibration of the clocks, so that the
drift rate changes by about 30-50PPM on each reboot. ntp must thus respond to
this change. Here is a plot of the response of ntp to one such change.

Chrony version 1.23 slightly modified in the rtc measurements by W Unruh
NTP version 4.2.0 before Jan 21.00, and 4.2.4p4 after Jan 21.0.
Plot of offset vs delay